I am not a Bioinformatician but I often want to do things Bioinformaticians say are easy. This is the first in a possible series of blogs about my experiences with Bioinformatics, text mining, etc. I’d be very happy to receive comments on the approaches I try or hints on how to do what I am trying to do more easily. For now I am not learning to program or run scripts from a command line. I am happy to try something in Galaxy.
Part of the reason for these posts is so I can remeber how to do this next time myself.
This is meant to be the non-Bioinformaticians way of doing things!
I used to just send an email to one of the Bioinformaticians at work but I couldn’t help but take the hint that they had work to do as well. So now I’ll usually try to find out if I can do what I want myself with publically available, usually web-based tools. I figure that even if I don’t succeed my trying is evidence I’m not just abusing their better experience. It also helps me better explain what I want so they don’t do some work for me and then I say how nice it is but it is not really what I thought I wanted after all.
UCSC Distributed Annotation Service (DAS):
The “DAS” server allows you to download data directly from UCSC. I suspect it is built to be queried from under the hood rather than through a URL. However it is an easy way to get the sequence from genomic coordinates so I like it.
There is a simple FAQ here. And a query for a sequnce looks like this http://genome.ucsc.edu/cgi-bin/das/hg18/dna?segment=chr2:51409549,51409749 which will return 200bp of sequence from chr2 in Hg19 build of the Human genome.
Here’s how I used DAS and other tools to design some primers from a SNP:
Designing PCR primers from an dbSNP rsID: I am hoping to design some PCR assays to look at regions around SNPs. I got a list of SNPs from a colleague wth lots of information about them position, alleles, MAF, etc. However I wanted to take this list and design PCR primers to all 24 SNPs as quickly as possible.
Getting SNP locations: I was already sent the locations along with rsID’s but I wanted to see if I could find them myself. I like UCSC and it is usually my first port of call when looking for sequence information. In this case I simply entered an rsID into the UCSC position/search box (Image:UCSC RsID search) and then clicked through the link (Image: UCSC rsID results). This gives me the all important location information, chr1:4181020-4181020 in the case of rs10799216.
Getting flanking sequence: I used Excel (not a bioinformaticians favourite tool) to create a UCSC DAS address (Image: Excel to create DAS address) to pull out the flanking regions 100bp either side of the SNP (Image: UCSC DAS results).
Designing suitable primers: I used the sequence results from the DAS query in Primer3 (image: Primer3 Input) wth the parameters Targets=100,2 (primers surronding the 2 bases at position 100), ProdcutSizeRange=30-75 (I want short products) and NumberToReturn=50 (50 sets of primers). Hey presto PCR primers (Image: Primer3 Output)
Now I can get on and order some primers to test in the lab, where I feel much more in my conmfort zone.
 |
| UCSC rsID search |
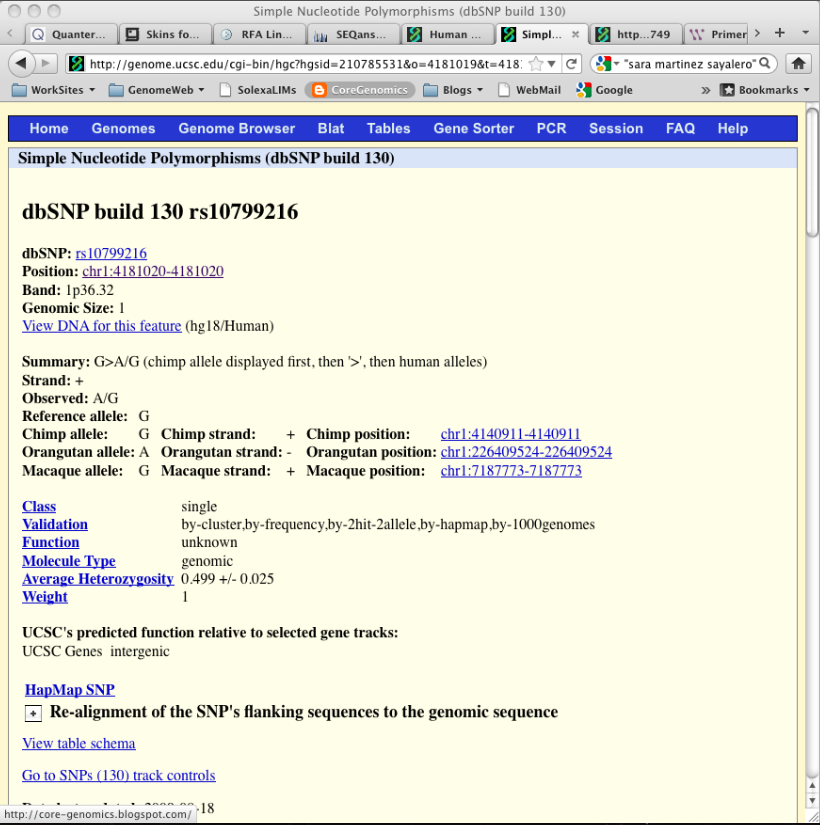 |
| UCSC rsID results |
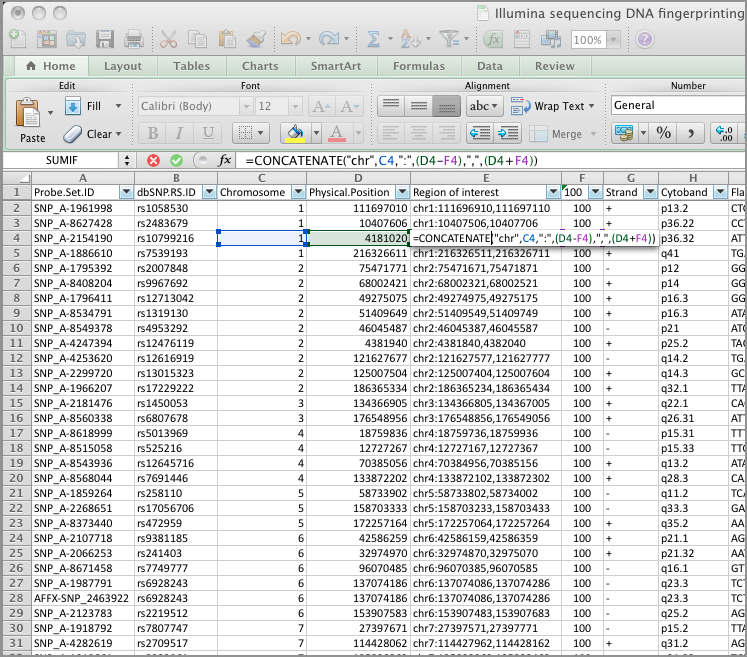 |
| Excel to create DAS address |
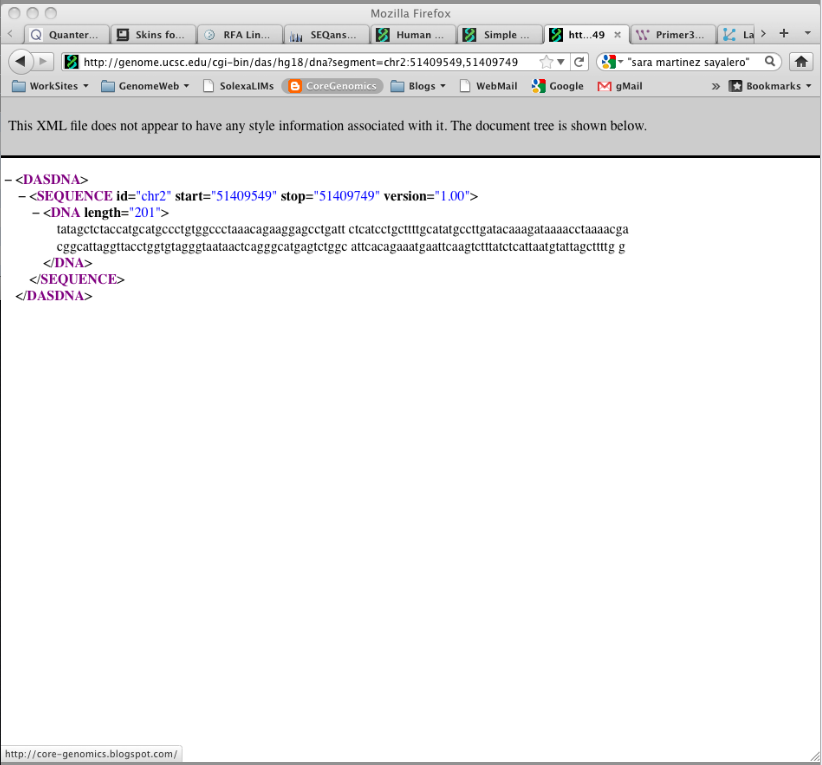 |
| UCSC DAS results |
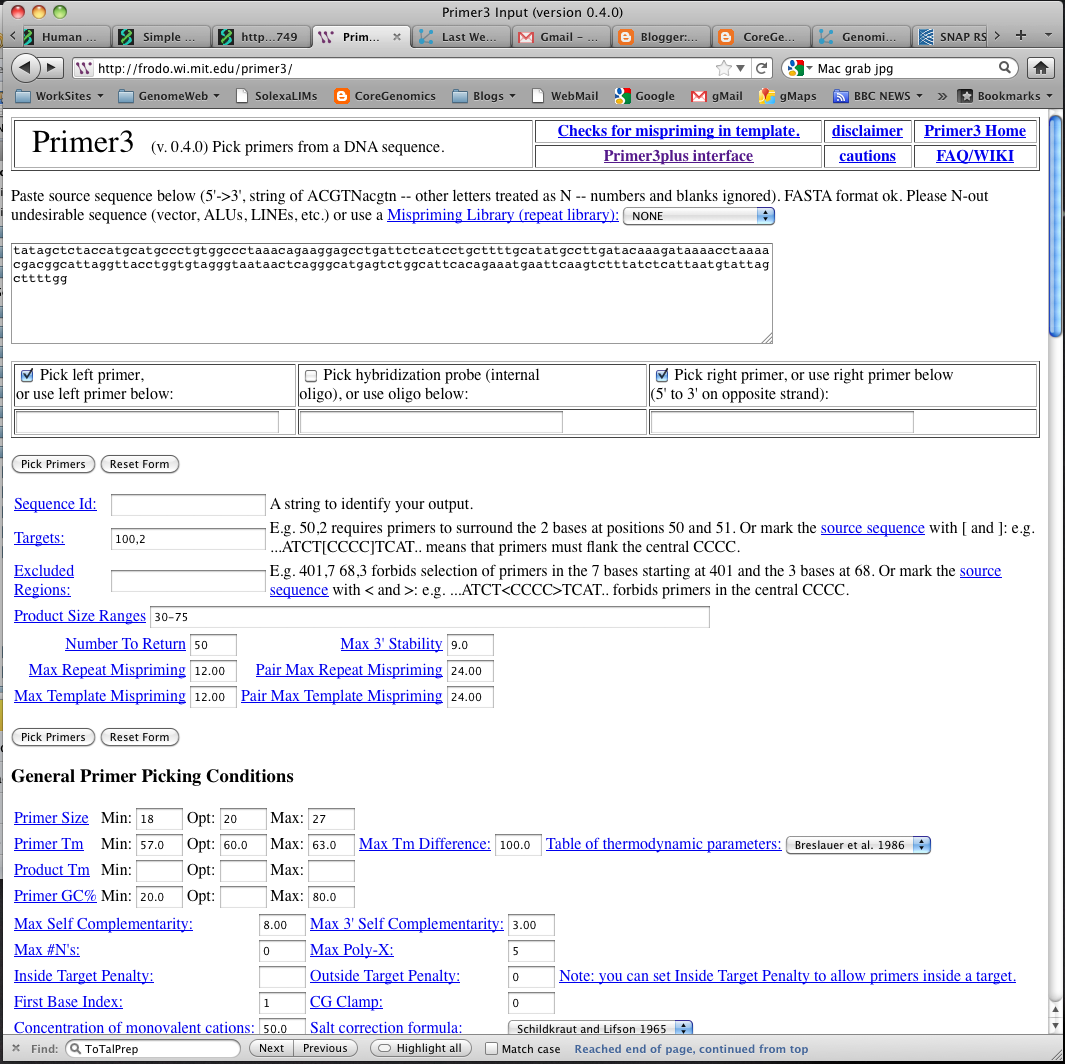 |
| Primer3 Input |
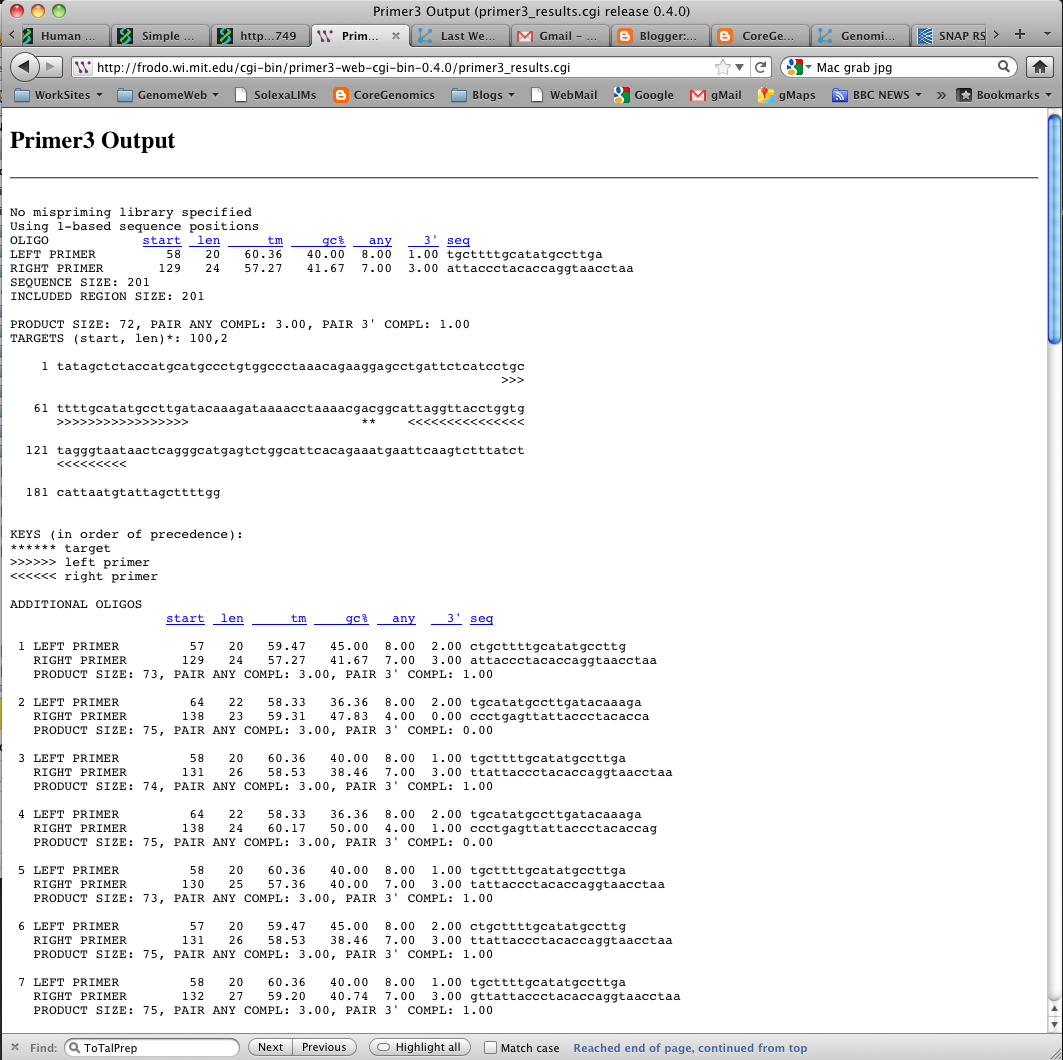 |
| Primer3 Output |
 |
| SNAP from the Broad |
 |
| SNAP query |
 |
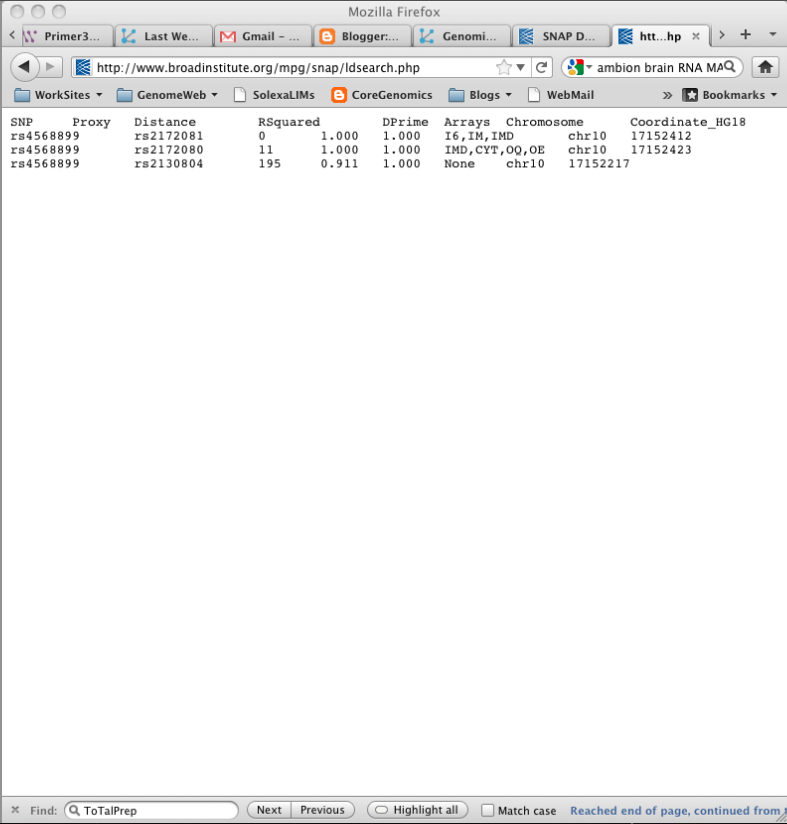
| SNAP results |
about the snp data and using excel and word to generate a DAS list and get data fast even though I’m not a bioinformaticiain!!!




{kind=link}
{kind=link}
Leave A Comment