A great new resource was recently brought to my attention on Twitter and there is a paper describing it on the BioRxiv: DNAmod: the DNA modification database. Nearly all of the modified nucleotide sequencing we hear and read about is modifications to Cytosine mostly methyl cytosine and hydroxymethyl cytosine; you may also have heard about 8-oxoG if you are interested in FFPE analysis. All sorts of modified nucleotides occur in nature and may be important in biological processes where they can vary across tissue of an organism, or may just be chemical noise. The modifications are most important when they change the properties of the DNA strand, how is is read, and what might or might not bind to it e.g mC.
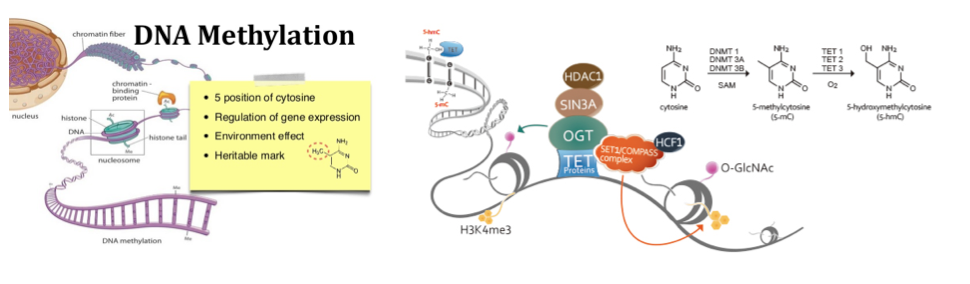
The biology of base modification is very complex – DNA methyltransferase marking Cytosine with a 5-methyl, TET family enzymes oxidising 5-methylcytosine to 5-hydroxymethylcytosine, and thymine DNA glycosylase-mediated base excision repair back to unmodified Cytosine. Many groups have worked on methods to sequence modified bases, with Shankar Balasubramanian’s research group here in Cambridge most closely associated with 5hmC-seq in his CEGX spinout.
 DNAmod DB: The DNA modification database lists 38 modified bases, only 7 of which only been observed synthetically. It gives each a brief description of each modified base including the likely biological function, and most importantly for readers of Core Genomics it lists the methods that can be used to map the modifications in the genome.
DNAmod DB: The DNA modification database lists 38 modified bases, only 7 of which only been observed synthetically. It gives each a brief description of each modified base including the likely biological function, and most importantly for readers of Core Genomics it lists the methods that can be used to map the modifications in the genome.Unfortunately it appears to miss the OxBS-seq method published by Booth et al in 2012, but does have the competing TAB-seq method published by Yu et al in the same year.
Not all bases are modified to the same extent: There are a total of 128 modified nucleotides reported in the unverified list on DNAmod. I’d assumed modifications would be about the same number for each of the biological building blocks but they vary quite significantly: Uracil has 45 mods (I’m guessing modifications in ribonucleotides need less careful control?), Adenine (39) has nearly twice as many modifications as Guanine (19), and Cytosine (13) and Thymine (12) have the least.
Citation: Sood AJ, Viner C, Hoffman MM. 2016. DNAmod: the DNA modification database. bioRxiv 071712.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
Thanks so much for your interest in DNAmod! I enjoyed reading your synopsis of this area.
We do actually include oxBS-seq. We list it under 5-methylcytosine (5mC; https://www.pmgenomics.ca/hoffmanlab/proj/dnamod/5-methylcytosine.html), in the final entry of its “Mapping techniques” table. We list sequencing methods only under the nucleobase(s) which they directly elucidate. Therefore, oxBS-seq is listed only under 5mC, while TAB-seq is listed only under 5-hydroxymethylcytosine (https://www.pmgenomics.ca/hoffmanlab/proj/dnamod/5-(hydroxymethyl)cytosine.html). We explain this in greater detail in the Discussion of our pre-print (https://doi.org/10.1101/071712).
Finally, we would like to caution against making any assumptions about the frequency of unmodified nucleobases being covalently modified, based on DNAmod. Our unverified list is directly imported from ChEBI, as any entity that has an unmodified base (A, T, G, C, or U) as an eventual functional parent. The distribution of items it contains is therefore coincidental, depending upon other factors like an entity's biological importance in unrelated areas.
And thanks for clarifying Coby. I understand the caution about assuming too much from the numbers – I'm wondering if anyone else has looked at this in detail as maybe Cytosine and Thymine have fewer mods because they are being used biologically so are constrained?
Nice tool for people to use!
I think that is an interesting question. I am not aware of any work that looks at in vivo propensity of DNA modification. I suspect this might be challenging to pursue in the general case, given the diverse functions and contexts of modifications (e.g. hypermodified bases in bacteriophages vs. bacterial modifications primarily involved in the restriction-modification system vs. eukaryotic epigenetic marks).
Thank you for your positive feedback on DNAmod.
It might be possible to analyze that in a particular sample using mass spectrometry, which has been used to quantify the amount of known modifications, at least.
Would be amazing to investigate all those mutations using Nanopore sequencing, afraid we aren't there yet (besides mc and hmc)